| Cluster | Age | Education_Level | Marital_Status | Children | Income | Answered_Cmps | Days_as_Customer | Recency | Total_Spent | MntWines | MntFruits | MntMeatProducts | MntFishProducts | MntSweetProducts | MntGoldProds | TotalPurchases | NumDealsPurchases | NumWebPurchases | NumCatalogPurchases | NumStorePurchases | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 46.945111 | 1.048027 | 0.847341 | 0.831904 | 29063.375643 | 0.087479 | 370.895369 | 48.512864 | 81.084048 | 27.444254 | 5.406518 | 20.900515 | 7.518010 | 5.639794 | 14.174957 | 7.255575 | 1.787307 | 1.984563 | 0.433962 | 3.049743 |
| 1 | B | 60.658696 | 1.404348 | 1.036957 | 1.839130 | 42360.536957 | 0.091304 | 327.491304 | 50.278261 | 125.556522 | 74.956522 | 3.363043 | 25.656522 | 4.836957 | 3.328261 | 13.415217 | 9.363043 | 2.619565 | 2.460870 | 0.689130 | 3.593478 |
| 2 | C | 58.238342 | 1.471503 | 1.015544 | 1.098446 | 56785.852332 | 0.323834 | 417.626943 | 48.176166 | 651.220207 | 444.225389 | 14.715026 | 111.608808 | 19.652850 | 13.790155 | 47.227979 | 19.917098 | 3.616580 | 6.038860 | 2.810881 | 7.450777 |
| 3 | D | 57.796117 | 1.422330 | 0.966019 | 0.504854 | 70724.033981 | 0.611650 | 378.223301 | 47.786408 | 1139.300971 | 629.490291 | 38.262136 | 315.388350 | 63.669903 | 45.286408 | 47.203883 | 21.757282 | 1.980583 | 5.762136 | 5.252427 | 8.762136 |
Segmentação de clientes com Machine Learning
Contexto
Uma empresa do varejo deseja aumentar suas vendas e otimizar campanhas de marketing, isto é, enviar campanhas específicas para públicos específicos pensando em um maior retorno sobre o investimento (ROI). Para isso, ela conta com uma base de dados contendo informações sobre clientes como: (i) apsectos demográficos, (ii) padrões de compra e (iii) resultados de campanhas de marketing passadas.
Nesse sentido, implementar um algoritmo de agrupamento (clusterização) sobre essa base pode ser de grande valia para o négócio.
O método utilizado nesse projeto foi o CRISP-DM e a execução se deu via linguagem de programação Python.
Entendimento do negócio
Objetivo
Segementar essa base de clientes de modo a obter grupos com personas bem definidas, que ajudem o negócio a tomar melhores decisões.
Premissas
Como premissas para o projeto, tem-se:
- A base de clientes é uma amostra representativa da população.
- A coleta de dados se deu aleatoreamente e sem viéses de seleção.
- Os dados são de boa qualidade e atualizados.
Critérios de sucesso
Identificar no mínimo dois ou mais grupos de clientes, de forma que o negócio consiga entender cada grupo e promover uma boa experiência ao cliente ao longo do seu ciclo junto à empresa.
Entendimento dos dados
Os dados correspondem 2240 linhas e 28 colunas referentes a dados dos clientes, bem como resultados de campanhas de marketing. O dataset apresenta como dicionário de dados:
| Coluna | Descrição |
|---|---|
ID |
Identificador único do cliente |
Year_Birth |
Ano de nascimento do cliente |
Education |
Nível de educação do cliente |
Marital_Status |
Estado civil do cliente |
Income |
Renda anual da família do cliente |
Kidhome |
Número de crianças na família do cliente |
Teenhome |
Número de adolescentes na família do cliente |
Dt_Customer |
Data de inscrição do cliente na empresa |
Recency |
Número de dias desde a última compra do cliente |
MntWines |
Valor gasto em vinho nos últimos 2 anos (em U$D) |
MntFruits |
Valor gasto em frutas nos últimos 2 anos (em U$D) |
MntMeatProducts |
Valor gasto em carne nos últimos 2 anos (em U$D) |
MntFishProducts |
Valor gasto em peixe nos últimos 2 anos (em U$D) |
MntSweetProducts |
Valor gasto em doces nos últimos 2 anos (em U$D) |
MntGoldProds |
Valor gasto em produtos Premium nos últimos 2 anos (em U$D) |
NumDealsPurchases |
Número de compras feitas com desconto |
NumWebPurchases |
Número de compras feitas através do site da empresa |
NumCatalogPurchases |
Número de compras feitas usando um catálogo |
NumStorePurchases |
Número de compras feitas diretamente em lojas |
NumWebVisitsMonth |
Número de visitas ao site da empresa no último mês |
AcceptedCmp3 |
1 se o cliente aceitou a oferta na 3ª campanha, 0 caso contrário |
AcceptedCmp4 |
1 se o cliente aceitou a oferta na 4ª campanha, 0 caso contrário |
AcceptedCmp5 |
1 se o cliente aceitou a oferta na 5ª campanha, 0 caso contrário |
AcceptedCmp1 |
1 se o cliente aceitou a oferta na 1ª campanha, 0 caso contrário |
AcceptedCmp2 |
1 se o cliente aceitou a oferta na 2ª campanha, 0 caso contrário |
Response |
1 se o cliente aceitou a oferta na última campanha, 0 caso contrário |
Complain |
1 se o cliente reclamou nos últimos 2 anos, 0 caso contrário |
Country |
País do cliente (localização) |
A base original continha alguns dados ausentes, outliers (valores discrepantes) e colunas categóricas que precisaram ser codificadas (em rótulos numéricos). Em resumo, obteve-se os seguintes insights da análise exploratória:
- Os clientes possuem entre 24-84 anos, com média em torno de 55 anos.
- Cerca de 89% dos clientes possuem ensino superior.
- A base conta com estados civis de: solteiro, casado, divorciado e viúvo. Aproximadamente 35% da base vive sem um companheiro (65% é casado).
- Cerca de 28% da base não tem filhos, enquanto 72% possui um ou mais filhos.
- Tem-se várias faixas de renda entre os clientes, com mínimo de 1.730 USD, máximo de 154.000 USD, média de 52.200 USD anuais (desconsiderando outliers) e desvio padrão de \(\sim\) 20.700 USD.
- Cerca de 84% dos clientes não responderam nenhuma campanha, enquanto 16% responderam no mínimo 1 campanha.
O notebook Python completo contendo a etapa de EDA e modelagem pode ser encontrado em aqui.
Colunas excluídas da análise:
NumWebVisitsMonth: não necessariamente as visitas convertem em compra, logo foi decidido pelo negócio a exclusão dessa coluna na fase de modelagem.Complain: 99% dos clientes não reclamaram, logo, essa coluna não contribuiria muito para a modelagem.Response: se refere à compra, mas apenas na última campanha enviada, pouco representativa para o problema em questão.
Colunas modificas/novas colunas:
Year_Birthfoi substituída porAge(cálculo de datas)Educationfoi substituída porEducation_Levelque divide os clientes quanto a: (i) Ensino Básico, (ii) Graduação e (iii) Pós-Graduação.Dt_customerfoi substituída porDays_as_Customer(data máxima do dataset - data inicial como cliente)KidhomeeTeenhomeforam unificadas emChildren(número de filhos totais)- Colunas do tipo
AcceptedCmp...foram derivadas emAcceptedCmps(número de campanhas aceitas) - Nova coluna:
TotalPurchases(Total de compras, somando todos os canais de venda)
Preparação dos dados
Nessa etapa foram calculadas correlações entre as variávies, colunas numéricas foram padronizadas em função de possuírem diferentes escalas. Já as colunas categóricas, estas foram codificadas da seguinte forma:
| Coluna | Rótulos |
|---|---|
| Escolaridade | Básico: 0, Graduação: 1, Pós-graudação: 2 |
| Estado civil | Solteiro: 0, Casado: 1, Divorciado: 2, Viúvo: 3 |
Para o treino do modelo, utilizou-se as colunas:
‘Age’, ‘Education_Level’, ‘Marital_Status’, ‘Children’, Income’, ‘Answered_Cmps’, ‘Recency’, ‘Total_Spent’, ‘MntWines’, ‘MntFruits’, ‘MntMeatProducts’, ‘MntFishProducts’, ‘MntSweetProducts’, ‘MntGoldProds’, ‘TotalPurchases’
O conjunto de dados pós-processamento e limpeza constou em 1635 linhas e 15 colunas.
Modelagem
A etapa de modelagem se deu via algoritmo K-means, um algoritmo de aprendizado não-supervisionado destinado a tarefas de agrupamento (ou clusterização). Antes de entrar na modelagem, observou-se pelas colunas categóricas e com base na renda anual (coluna numérica), um número de grupos sugestivo para a modelagem:
Formação:
- Básica
- Graduação
- Pós-graduação
Estado civil:
- Solteiro
- Casado
- Divorciado
- Viúvo
Filhos:
- Nenhum
- Um filho
- Dois ou mais filhos
Logo, 3-4 clusters já seria um bom chute inicial (o número foi posteriormente validado pelo método do cotovelo). Quanto ao funcionamento, o algoritmo K-means (Figura 1) funciona da seguinte maneira:
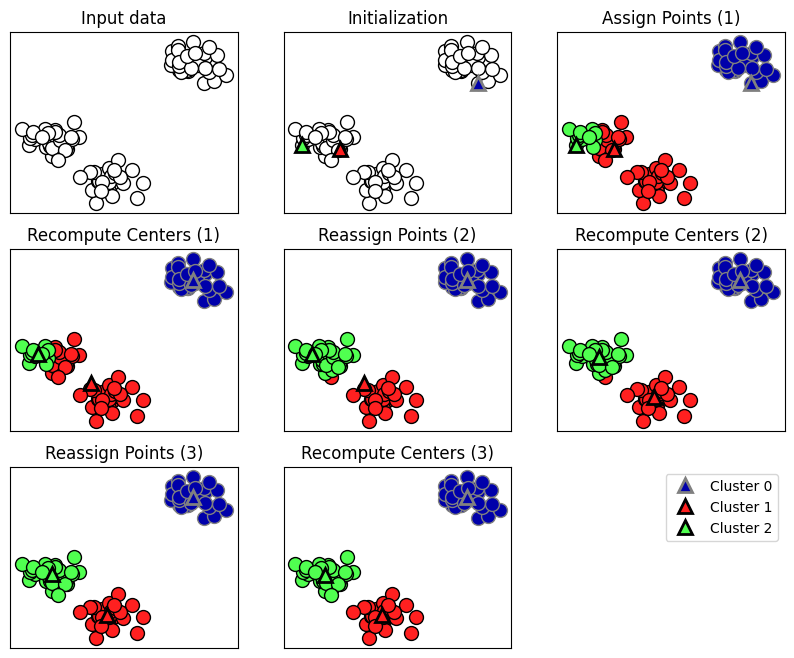
- É informado um número de clusters inicial (cujo centro de cada cluster é calculado);
- A distância de cada ponto versus o centro de cada cluster é calculada. Dessa forma, atribui-se a cada observação o cluster cuja distância em relação ao seu centro é menor.
- Com as observações rotuladas, recalcula-se os novos centros de cada cluster e as distâncias de cada observação novamente. Ao final dessa etapa, tem-se os clusters atualizados.
- Repete-se o processo até que a configuração dos clusters não se altere significativamente.
Conforme mencionado anteriormente:
O notebook Python completo contendo a etapa de EDA e modelagem pode ser encontrado em aqui.
Resultados
O que mais contribuiu para discriminar os clusters - com base na análise de correlação de cada variável da modelagem com a coluna Cluster foi:
| Coluna | Correlação (poder de discriminação) |
|---|---|
| Quantidade de filhos | 64% |
| Total Gasto | 39% |
| Idade | 32% |
| Compras | 18% |
| Campanhas respondidas | 16% |
| Escolaridade | 13% |
| Renda | 9% |
| Estado civil | 9% |
Quanto à distribuição, tem-se:
| Cluster | Clientes | Percentual |
|---|---|---|
| A | 583 | 36% |
| B | 460 | 28% |
| C | 386 | 24% |
| D | 206 | 12% |
Abaixo, tem-se um resumo dos clusters, tomando a média como medida de tendência central:
Segmentando um pouco por fatores como aspectos demográficos, recência/frequência/valor, tem-se:
Aspectos demográficos:
| Age | Children | Income | Marital_Status | Days_as_Customer | Education_Level | |
|---|---|---|---|---|---|---|
| Cluster | ||||||
| A | 46.00 | 1.00 | 28718.00 | 1.00 | 360.00 | 1.00 |
| B | 60.00 | 2.00 | 42602.00 | 1.00 | 306.50 | 1.00 |
| C | 58.00 | 1.00 | 57081.50 | 1.00 | 432.50 | 2.00 |
| D | 59.00 | 0.00 | 70596.00 | 1.00 | 371.50 | 1.00 |
Pela mediana, podemos notar rapidamente que:
- A idade dos clientes do cluster A é menor os clusters B, C, D.
- Clusters com 1 filho: A e C. Cluster com 2 filhos: B. Cluster sem filhos: D.
- Em todos os clusters, a maioria dos clientes é casada.
- O cluster C é o cliente mais fidelizado (maior tempo como cliente, 432 dias).
- Clusters A, B e D: usualmente possuem graduação. Cluster C: pós-graduação.
- Existem quatro faixas de renda.
Recência, frequência e valor:
| Cluster | Recency | TotalPurchases | Total_Spent | NumDealsPurchases | Ticket | Percent_DealsPurchase | |
|---|---|---|---|---|---|---|---|
| 0 | A | 48.00 | 7.00 | 58.00 | 1.00 | 8.29 | 14.29 |
| 1 | B | 51.00 | 9.00 | 84.50 | 2.00 | 9.39 | 22.22 |
| 2 | C | 50.00 | 19.00 | 570.50 | 3.00 | 30.03 | 15.79 |
| 3 | D | 48.00 | 21.00 | 1149.00 | 1.00 | 54.71 | 4.76 |
Novamente, pela mediana, tem-se que:
- A recência é similar entre os clusters.
- Os clusters C e D compram com mais frequência que os clusters A e B.
- Os quatro perfis de renda implicam em diferentes comportamentos quanto ao total gasto.
- Os clusters B e C costumam comprar mais com desconto. O cluster D quase não compra com desconto.
- Clusters A e B: baixo ticket médio (total gasto dividido pelo total de compras). Clusters C e D: alto ticket.
Vejamos tais aspectos por meio de visualizações interativas (você pode dar zoom, filtrar clusters e obter informações ao passar o mouse).
Idade
- Cluster A: média em torno de 46 anos
- Clusters B, C, D: média em torno de 60 anos
Renda anual (USD)
- Cluster A: baixa renda
- Cluster B: média renda
- Cluster C: renda média-alta
- Cluster D: alta renda
Isso interfere no quanto o cliente gasta na empresa:
Clientes da base que têm maior renda, tendem a gastar mais. Mas aonde cada cluster gasta?
Padrões de compra por cluster
| Cluster | Total_Spent | MntWines | MntFruits | MntMeatProducts | MntFishProducts | MntSweetProducts | MntGoldProds | |
|---|---|---|---|---|---|---|---|---|
| 0 | A | 58.00 | 20.69 | 5.17 | 22.41 | 6.90 | 5.17 | 17.24 |
| 1 | B | 84.50 | 50.89 | 1.18 | 20.12 | 2.37 | 1.18 | 10.06 |
| 2 | C | 570.50 | 66.52 | 1.75 | 17.53 | 2.28 | 1.75 | 6.84 |
| 3 | D | 1149.00 | 53.05 | 3.05 | 26.15 | 5.44 | 3.74 | 3.66 |
- Cluster A: Gasta mais com frutas, peixes, doces e, de certa forma, acaba comprando produtos premium (talvez em ofertas)
- Cluster B: gasta mais com vinhos, produtos premium e carnes
- Cluster C: gasta mais com vinhos e produtos premium
- Cluster D: gasta mais com vinhos, carnes, peixes e doces.
Vejamos isso por meio de visualizações:
Valor gastos em vinhos:
Valor gastos em carnes:
Valor gastos em peixe:
Valor gastos em produtos premium:
Valor gastos em doces:
Valor gastos em frutas:
Campanhas de marketing
- Os clusters A e B parecem responder menos a campanhas de marketing.
Canais de venda
Compras na loja:
Compras online:
- Clusters A e B compram online e na loja.
- Clusters C e D também compram online e na loja, mas o volume de compras na loja parece ser um pouco maior.
Compras com desconto:
- O cluster D tem muitos clientes que não compram com desconto.
- O cluster C parece ser o mais “guiado” a descontos.
- Clusters B e C costumam comprar com desconto.
Personas
Cluster A (baixa renda, poucas compras, clientes mais novos): cliente com média 46 de anos, baixa renda, possui ensino superior, normalemente casado e aposentado, possui entre 0-1 filhos. Valoriza cada centavo gasto. Suas compras são guiadas por promoções e descontos, e não é fiel a marcas específicas. Sua resposta a campanhas de marketing é baixa, preferindo informações de fontes confiáveis e próximas, como amigos e redes sociais. Esse tipo de cliente busca sempre o melhor custo-benefício para atender às suas necessidades e de sua família. Embora gaste pouco, costuma empregar seu dinheiro mais nas categorias frutas, peixes, doces e produtos premium (este último em ofertas).
Cluster B (média renda, guiado por promoções): cliente com média de 60 anos, média renda, possui ensino superior, usualmente casado e aposentado, geralmente possui 2 filhos adultos. Suas compras são guiadas por promoções e descontos, também não sendo fiel a marcas específicas. Sua resposta a campanhas de marketing é baixa e esse tipo de cliente está sempre em busca de custo-benefício para atender às suas necessidades. Seu objetivo é economizar para garantir um futuro financeiro estável e aproveitar a aposentadoria sem preocupações. Gasta consideravelmente comparado ao cluster de baixa renda. Costuma gastar em vinhos e carnes.
Cluster C (renda média-alta, cliente fidelizado, guiado pelo mix de preço e valor): cliente com média de 60 anos, renda média-alta, pós-graduado, casado e normalmente possui 1 único filho. Valoriza produtos de excelência/marca e é um cliente fiel (grupo há mais tempo como cliente). Esse tipo de cliente compra tanto online quanto em lojas físicas e responde relativamente bem a campanhas de marketing. Além disso, pode-se dizer que é bem sensível a descontos. Suas compras são guiadas pela qualidade e pelo desejo de economizar sem comprometer a excelência dos produtos. Ele busca desfrutar de um estilo de vida sofisticado e tem como objetivo continuar explorando novas experiências gastronômicas. Costuma gastar mais com vinhos e produtos premium.
Cluster D (alta renda, cliente fidelizado, guiado por marca e qualidade): cliente com média de 60 anos, alta renda, normalmente possui graduação, casado(a) e sem filhos. Se trata de um público de clientes fieis e que responde muito bem a campanhas de marketing. Compra tanto online quanto em lojas físicas e não é sensível a descontos, preferindo produtos de alta qualidade e exclusividade. É o tipo de cliente mais rentável na base e suas compras são guiadas pela busca por qualidade e experiências premium. Além disso, infere-se que esse grupo deseja continuar explorando novas experiências sofisticadas e manter um estilo de vida confortável e farto. Gasta consideravelmente em vinhos, carnes, peixes e doces.
Recomendações gerais
- Buscar atrair mais clientes dos clusters B, C e D.
- Os clusters D e C compreendem os clientes de maior qualidade (mais rentáveis, maiores tickets, etc.). Como fidelizar ainda mais esse público? Quais marcas eles gostam mais?
- Buscar diminuir a recência da base de clientes. Para isso, pode-se fazer uso de experimentações com algum dos clusters.
- Reduzir o percentual de clientes do cluster A.
- Cluster B: foco em produtos de baixo ticket, de modo a gerar lucro em escala.
- Clusters C: foco em produtos de qualidade e com bom custo-benefício. Campanhas de marketing com ofertas personalizadas e promoções são bem-vindas.
- Cluster D: foco em produtos de alta qualdidade e que promovam um ótima experiência ao consumidor. Campanhas de marketing mais voltadas ao branding são interessantes para esse público. Não oferecer muitas promoções. Ter em mente que esse tipo de cliente está disposto a pagar mais pela qualidade.
Validação e deploy
Os clusters obtidos podem ser então entregues e discutidos com o negócio (bem como as recomendações). Se facilitar, os resultados podem ser consumidos via um dashboard ou na forma de planilhas - aqui se aplica o que melhor satisfazer a área de negócio. Por exemplo, é interessante possuir a informação do cluster de cada cliente em plataformas de CRM e email marketing.