O Python conta com inúmeras bibliotecas de visualização. Alguns exemplos são:
Matplotlib
Seaborn (baseada em matplotlib)
Plotly
Bokeh
Nesta seção vamos ver um exemplo em seaborn, com um toque de sotrytelling. Suponha o bloco de código e a respectiva saída a seguir. Nele temos um gráfico stripplot para o score de crédito dos clientes (cada ponto é um cliente).
# bibliotecas:import matplotlib.pyplot as pltimport seaborn as sns # gráfico de stripplot:fig, ax = plt.subplots()sns.stripplot( data=clientes_cifraonline, y='score_credito', color='lightgray', size=7, alpha=0.7, jitter=0.25, label='cliente')# layoutplt.xticks([]);plt.legend(loc='lower left')plt.ylabel('Score');plt.title('Score de crétido dos clientes ', weight='bold', loc='left');
Stripplot gerado com Seaborn
Vamos supor que se deseja responder à seguinte pergunta:
Quantos clientes tem o score de crédito acima de 700?
Se deseja responder essa pergunta, pois esses clientes com score maior ou igual a 700 têm um perfil muito interessante para o négocio. Todavia, como podemos comunicar isso de maneira bem visual? Abaixo, temos um singelo exemplo.
# Regra de negócio:clientes_cifraonline['performance_score'] = clientes_cifraonline['score_credito'].apply(lambda score: 'Sim'if score >=700else'Não')# Contagem de clientes com score maior ou igual a 700: contagem_clientes =len(clientes_cifraonline.query('performance_score == "Sim" '))percentual =round(contagem_clientes /len(clientes_cifraonline) *100, 2)# Visualização de dados:fig, ax = plt.subplots()sns.stripplot( data=clientes_cifraonline, y='score_credito', hue='performance_score', palette=['royalblue', 'lightgray'], size=7.5, alpha=0.7, jitter=0.25)plt.axhline( y=700, lw=1, ls='--', color='royalblue', label='Score 700')plt.title(f'Aproximadamente ({percentual}%) dos clientes têm score acima de 700', weight='bold', color='royalblue', loc='left', size=10);plt.legend().remove();
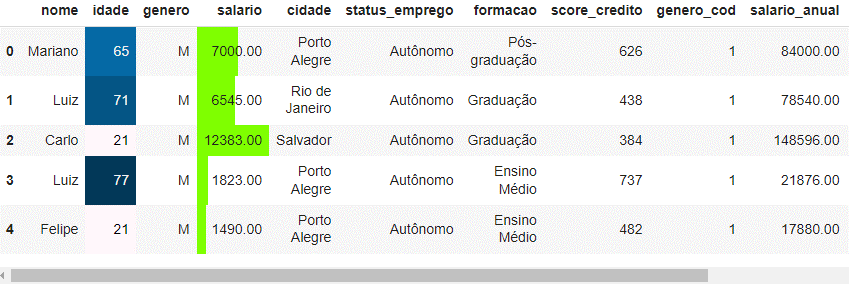
---title: "Manipulação de Dados com Pandas"author: "Vinícius Oviedo"format: bookup-html+darkonly: embed-fonts: true toc: true---# Visualização de dadosNesta aula, vamos trabalhar com métodos aplicáveis à limpeza de dados com `Pandas`. Veremos :1. Métodos de plotagem *built-in* do `Pandas`2. Um exemplo usando *seaborn*3. Como aplicar estilos em *dataframes*.Para isso, trabalharemos no conjunto de dados da última aula (pós-limpeza).```{python}import pandas as pdclientes_cifraonline = pd.read_csv('dados/clientes-banco-cifraonline/clientes_cifraonline_limpo.csv')clientes_cifraonline.head()```## 1. Métodos *built-in*> **Scatter plot**```pythonpd.options.plotting.backend ='matplotlib'clientes_cifraonline.plot.scatter(x='idade', y='salario')```{width=520}> **Gráfico de barras**:```pythonpd.options.plotting.backend ='matplotlib'clientes_cifraonline[['score_credito']].head(10).plot.barh(color='k',)```{width=520}> **Boxplot**```pythonpd.options.plotting.backend ='matplotlib'clientes_cifraonline['score_credito'].plot.box()```{width=520}Adicionalmente, podemos mudar a biblioteca por trás das plotagens. Seguem algumas opções:```pythonpd.options.plotting.backend ='matplotlib'# (default)pd.options.plotting.backend ='plotly'pd.options.plotting.backend ='pandas_bokeh'pd.options.plotting.backend ='hvplot'```Por exemplo, a biblioteca `plotly` é muito interessante nesses casos, pois traz interatividade ao gráfico. ```{python}# Desconsiderar este código (apenas ajuste de layout):import plotly.io as pio# Defina as configurações padrão para os gráficoslayout_defaults =dict( plot_bgcolor='rgb(28, 31, 43)', paper_bgcolor='rgb(28, 31, 43)', legend=dict(font=dict(color="white")), xaxis=dict(tickfont=dict(color="white"), gridcolor="white", linecolor="white"), yaxis=dict(tickfont=dict(color="white"), gridcolor="white", linecolor="white"), colorway=["white"])```> **Histograma com plotly**```{python}pd.options.plotting.backend ='plotly'histograma = clientes_cifraonline['score_credito'].plot.hist(template='simple_white', width=420, height=300)histograma.update_layout(layout_defaults)histograma.show()```> **Boxplot com plotly**```{python}pd.options.plotting.backend ='plotly'boxplot = clientes_cifraonline['score_credito'].plot.box(template='simple_white', width=350, height=300)boxplot.update_layout(layout_defaults)boxplot.show()```## 2. Bibliotecas de visualizaçãoO Python conta com inúmeras bibliotecas de visualização. Alguns exemplos são:1. Matplotlib2. Seaborn (baseada em matplotlib)3. Plotly4. BokehNesta seção vamos ver um exemplo em `seaborn`, com um toque de ***sotrytelling***. Suponha o bloco de código e a respectiva saída a seguir. Nele temos um gráfico *stripplot* para o score de crédito dos clientes (cada ponto é um cliente).```python# bibliotecas:import matplotlib.pyplot as pltimport seaborn as sns # gráfico de stripplot:fig, ax = plt.subplots()sns.stripplot( data=clientes_cifraonline, y='score_credito', color='lightgray', size=7, alpha=0.7, jitter=0.25, label='cliente')# layoutplt.xticks([]);plt.legend(loc='lower left')plt.ylabel('Score');plt.title('Score de crétido dos clientes ', weight='bold', loc='left');```{width=740}Vamos supor que se deseja responder à seguinte pergunta:> Quantos clientes tem o **score de crédito** acima de 700?Se deseja responder essa pergunta, pois esses clientes com score maior ou igual a 700 têm um perfil muito interessante para o négocio. Todavia, como podemos comunicar isso de maneira bem visual? Abaixo, temos um singelo exemplo.```python# Regra de negócio:clientes_cifraonline['performance_score'] = clientes_cifraonline['score_credito'].apply(lambda score: 'Sim'if score >=700else'Não')# Contagem de clientes com score maior ou igual a 700: contagem_clientes =len(clientes_cifraonline.query('performance_score == "Sim" '))percentual =round(contagem_clientes /len(clientes_cifraonline) *100, 2)# Visualização de dados:fig, ax = plt.subplots()sns.stripplot( data=clientes_cifraonline, y='score_credito', hue='performance_score', palette=['royalblue', 'lightgray'], size=7.5, alpha=0.7, jitter=0.25)plt.axhline( y=700, lw=1, ls='--', color='royalblue', label='Score 700')plt.title(f'Aproximadamente ({percentual}%) dos clientes têm score acima de 700', weight='bold', color='royalblue', loc='left', size=10);plt.legend().remove();```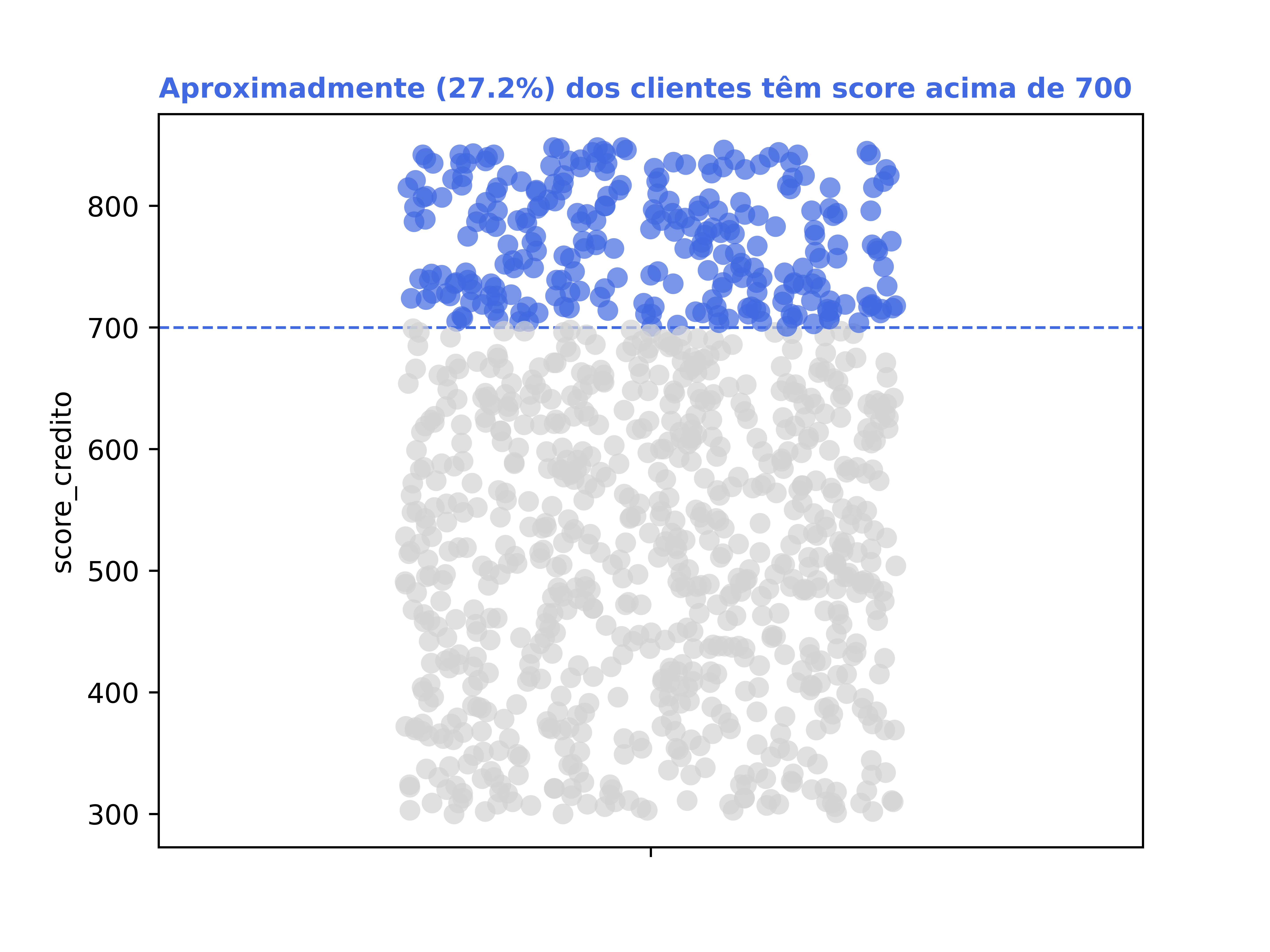{width=750}## 3. Estilos```pythonclientes_cifraonline.head().style.format(precision=2)\ .background_gradient()```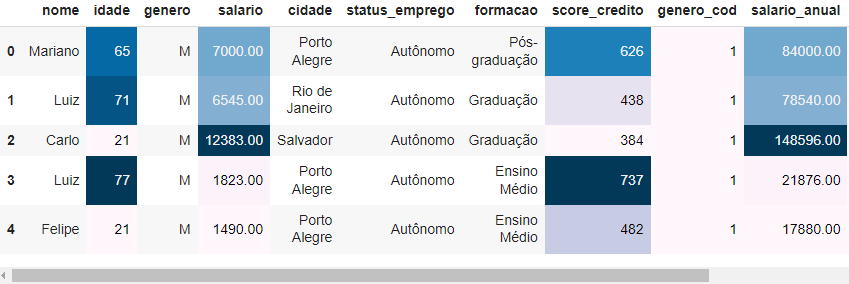```pythonclientes_cifraonline.head().style.format(precision=2)\ .bar(color='chartreuse')```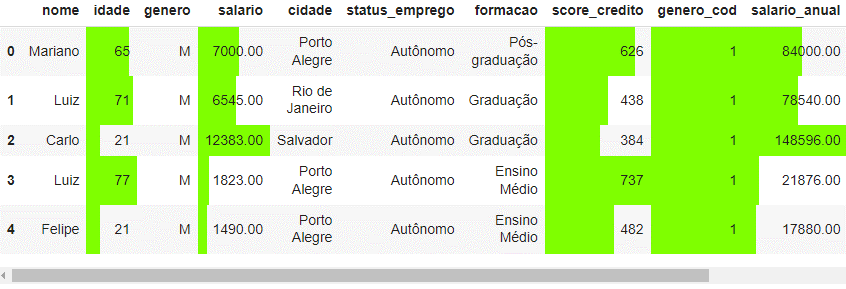```pythonclientes_cifraonline.head().style.format(precision=2)\ .bar(subset='salario', color='chartreuse')```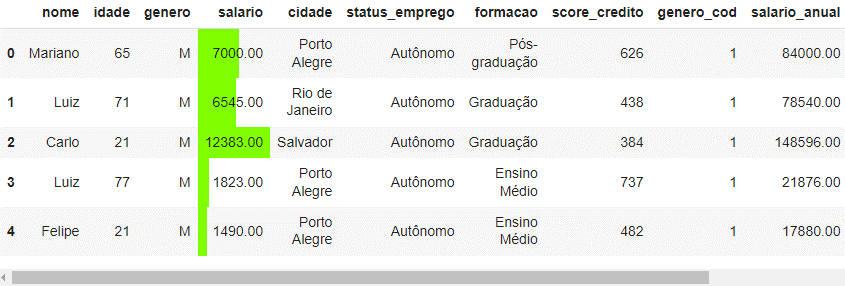```pythonclientes_cifraonline.head().style.format(precision=2)\ .highlight_between(subset='idade', left=60, right=75, color='orange')```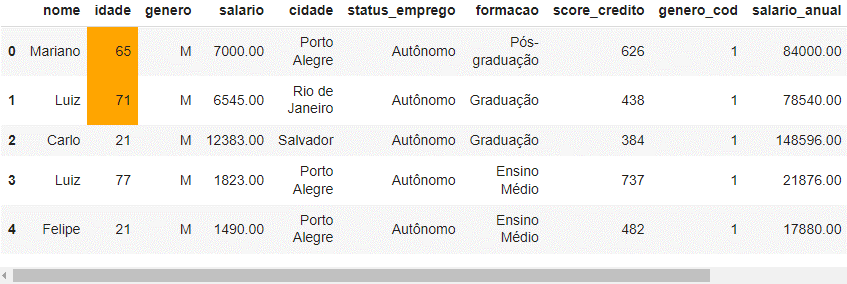```python# Criando uma função definida:def estilizar_dataframe(style): style.format(precision=2).bar(subset='salario', color='chartreuse') style.format(precision=2).background_gradient(subset='idade')return style# Aplicação:clientes_cifraonline.head().style.pipe(estilizar_dataframe)```